Connector Improvement: Pipedrive schema discovery to minimize initial API token consumption

Problem
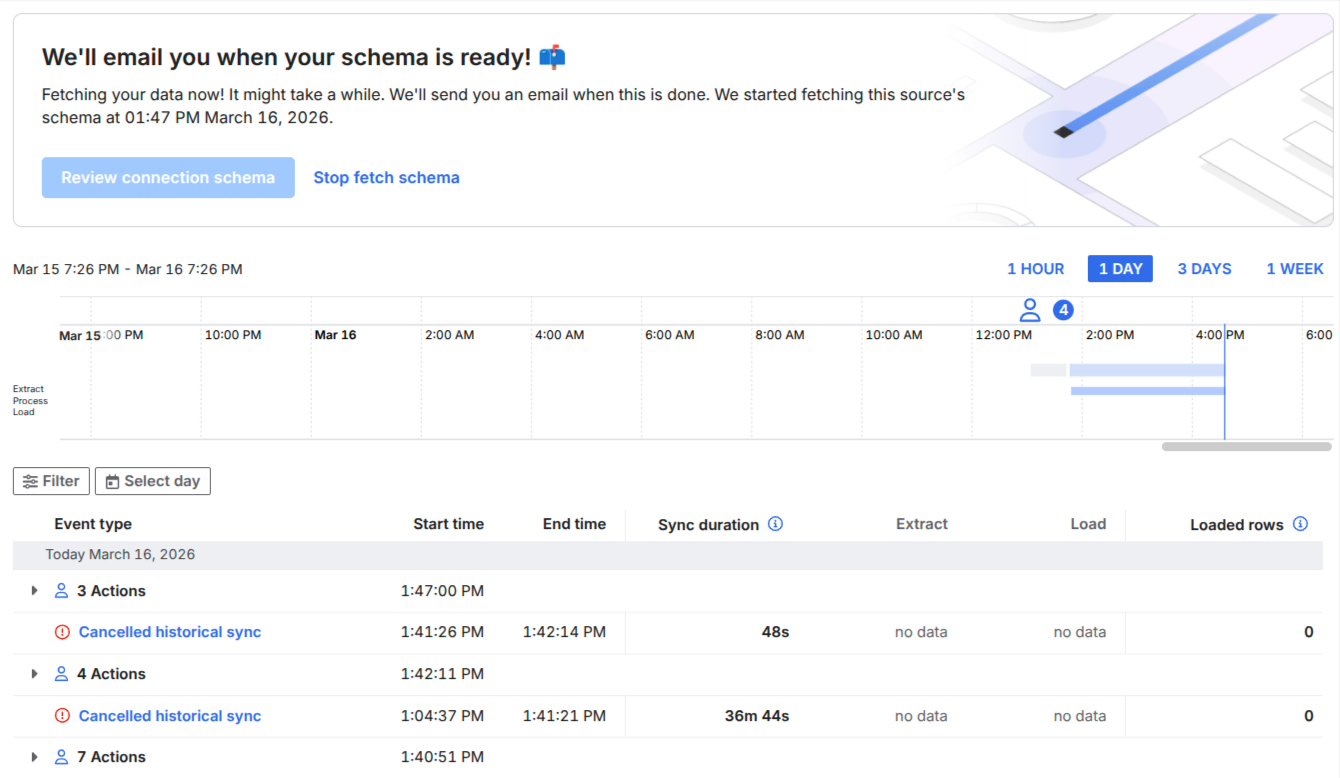
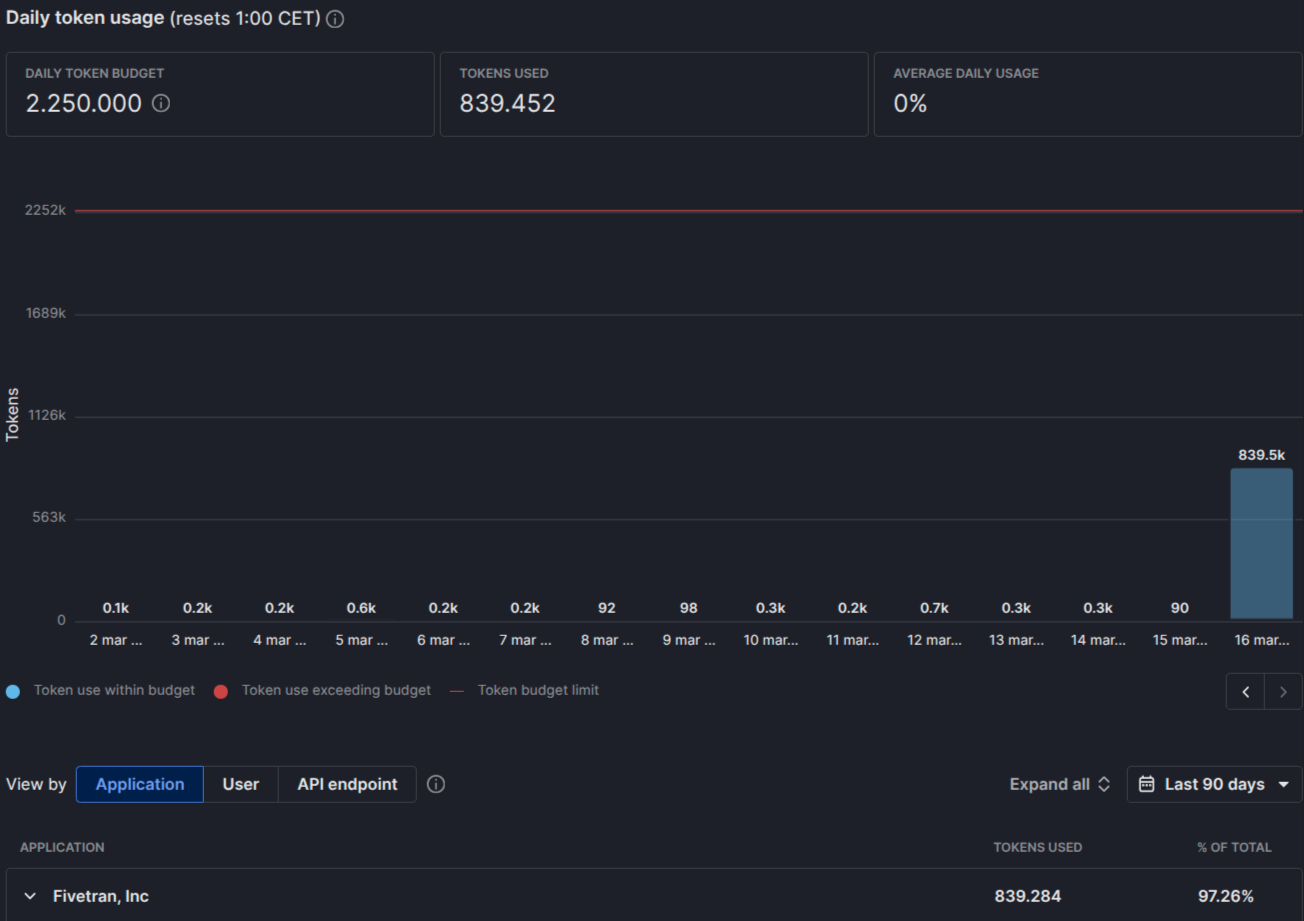
The current schema discovery process is overly resource-intensive. Before a user can select specific tables for synchronization, the connector must perform a full schema fetch, which, in our experience, can consume over 1 million Pipedrive API tokens and take three or more hours just to populate the schema list. This is highly inefficient and risks hitting the daily API limit before any actual data is synced.
Proposed Solution
Allow users to select tables based on the predefined ER diagram before the initial fetch is initiated. This would prevent the need for a full, token-intensive discovery step for every resource, enabling users to choose only the necessary tables and drastically limiting the initial API calls
-
Official comment

Hey, Abdul from the product team here. Thanks for reporting this, the token consumption you’re seeing during setup is way high and ideally shouldn’t be happening. I’m investigating and will follow.
On selecting tables before the fetch, we currently need to check which Pipedrive endpoints your plan has access to, which is why we run a discovery step first. But that check alone shouldn’t usually cost the high number of tokens you're seeing, let me review and get back to you.
Please sign in to leave a comment.
Comments
1 comment