Connector Improvement: Parse additional items from segment
Answered
Hi,
Please refer to #315006 and #308539 support ticket for details on this request.
We need to parse additional data from segment. For example, in the following screenshot, we have things like "context-device-id", and "context-advertising-id" that are very valuable information that doesn't show up as columns in fivetran connector. These are mandatory information for us to run jobs downstream.
Please assist.
Judy
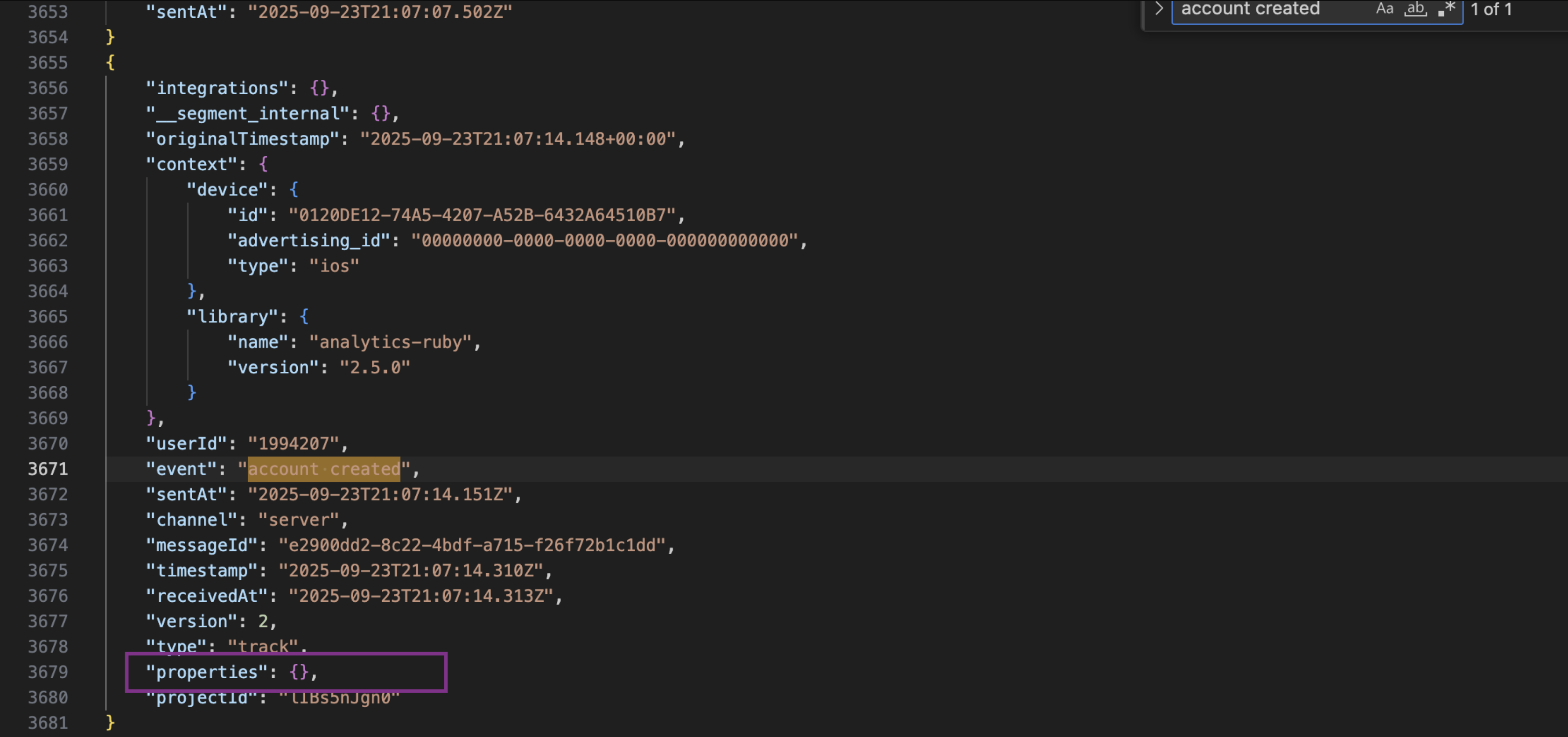
-
Official comment

Hi Judy,
Thanks for submitting this request and for sharing that you've already discussed this with our support team.I'm discussing this with our engineering team to get more context on this gap so we can determine the best way to address your request. My understanding is that you're requesting more than just "context-device-id" and "context-advertising-id" and that there are also tables that are "missing" that you'd like added too.
I'll post another update here after discussing this with the team.
Thanks,
Luke -
Hi Luke,
correct. we'd like to have all of these keys displayed. so not just context-device-id, but also userId, event, sentAt, etc. Plus, when the properties field is empty, we'd like to have all these other key-value pairs inserted as well.
For the missing tables, i'm not sure if that's achievable on ur side. We were trying to get some tables that originally syncs from segment to redshift into segment -> fivetran -> databricks instead. there was 1 table that only had data from 2 years ago. when we built the fivetran connection, it's normal that these tables are not there in the fivetran results. but we are not certain how to handle the case of new data appearing for this table. If we create a schema manually in databricks for this table right now, if new data appears, is it going to append into this table? Or will it show an error? If it shows an error I think it's a desired result. Just wanted to clarify the issue with the missing table with u here.
Please sign in to leave a comment.
Comments
2 comments