Other: HVR - Handling DBMS errors
Answered
We would like to have a feature to handle the HVR F_JD1202: DBMS error, to retry for certain duration before raising it as error. We can have a action param to configure this based on error codes.
Currently, we have seen instances where this error occurs and gets auto resolved but a pile on incidents gets created and to mitigate this we would like the above feature.
Case for reference/details: #281030
-

Hi Santosh,
I reviewed your support ticket. But I am still a bit puzzled what you are looking for.
As the support analyst showed you HVR will automatically retry. You have some control over the retry frequency. However, I'd like to think the defaults are not bad.
What was not discussed in the ticket is alerting. If you don't want certain alerts then these should be disabled/filtered out. We are making numerous changes to the alert setup - quite a bit of which is available in HVR 6.2.5 - that allows for more flexibility in defining alerts.
Am I correct assuming that between retry and flexibility on when to send alerts you should be able to manage the environment?
Thank you,
Mark. -
Hi Mark,
We do not want to raise the error upfront for the DBMS (integrate) connectivity issue until the retry fails.
Thanks,
Cheers -
Santosh,
When you configure an alert you can specify the ignore pattern. I recommend you use that to avoid escalating the issue.
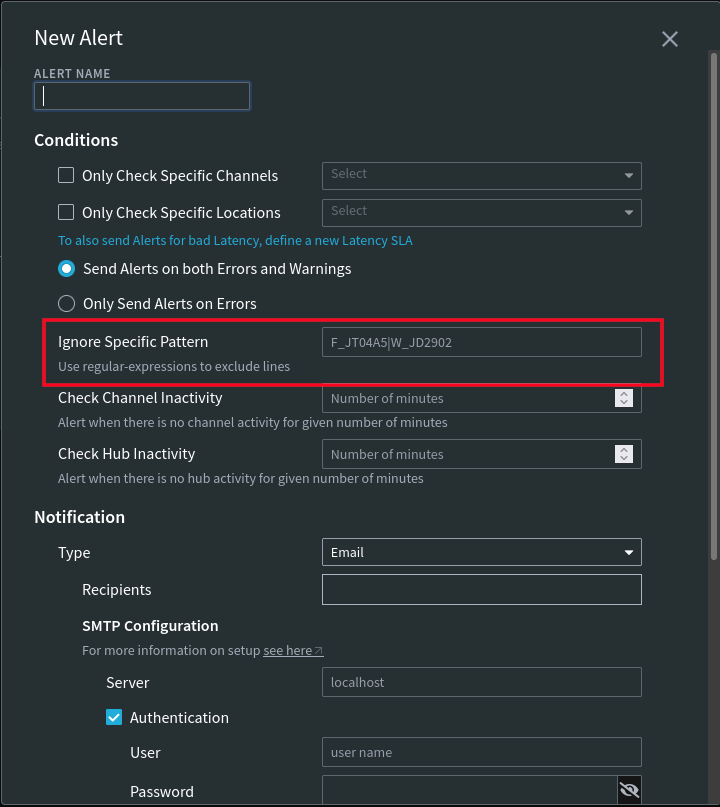
HVR would always log the message because it may point to an infrastructure issue that one should look into. Or, f subsequently the channel ends up with a lot of latency then we must know what happened.
Hope this helps.
Mark.
-
Hi Mark,
Setting up the alerts won't help us in this case. Once the error is logged this information is sent to splunk and an incident is created for all the encountered errors.
We want to avoid these errors for the first attempt and would like to apply a try and catch scenario where it will check the connection to destination and wait until next retry before raising it as error. This will resolve the issue which we have currently for generating 300+ incidents.Cheers,
Santosh -
Hi Mark, Will you be able to see if this feature reqauest is still under investigation?
-
Santosh,
Would it work for you if we gave you the option to completely suppress an error (e.g. based on the error code)?
Or is your perspective that you don't want it unless it takes more than <x> amount of time to get passed the error?
For the former suggestion I am concerned that you may not know the root cause of an issue that prevents replication from working. For the latter suggestion I am worried that you will want a very complex system to define when and how frequently you want to see certain errors (e.g. based on type of error channel or location i.e. SLAs, perhaps table-level options, etc).
Thanks,
Mark. -
Hi Mark,
Thanks for getting back on the request.-> is your perspective that you don't want it unless it takes more than <x> amount of time to get passed the error?
This sounds want we would need, we can setup an action to retry for the mentioned error for certain duration and then throw an error. Just like a try/catch block.
Please sign in to leave a comment.
Comments
7 comments