Connector Improvement: Separate `start_date` and `activated_date` in `sprint` table for Jira Data Center On-Premise

Currently `activated_date` overwrites `start_date` once Sprint is started, whereas `complete_date` and `end_date` are stored in separate columns.
Not only is `start_date` lost/erased, users are also confused when the two sets of similar dates are stored in different manners.
Fivetran Output:
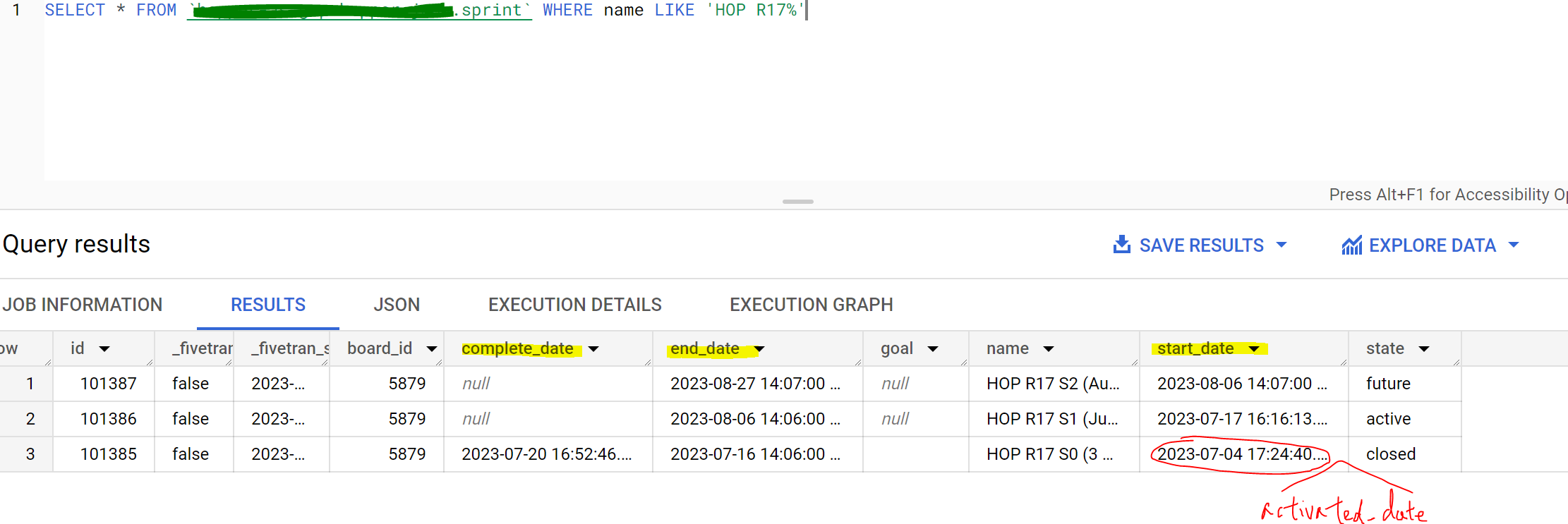
Jira API Output:
{
"id": 101385,
"self": (deleted for privacy),
"state": "closed",
"name": "HOP R17 S0 (3 Jul - 14 Jul)",
"startDate": "2023-07-02T14:06:00.000Z",
"endDate": "2023-07-16T14:06:00.000Z",
"completeDate": "2023-07-20T16:52:46.545Z",
"activatedDate": "2023-07-04T17:24:40.886Z",
"originBoardId": 5879,
"goal": ""
}
Jira Sprint Report:
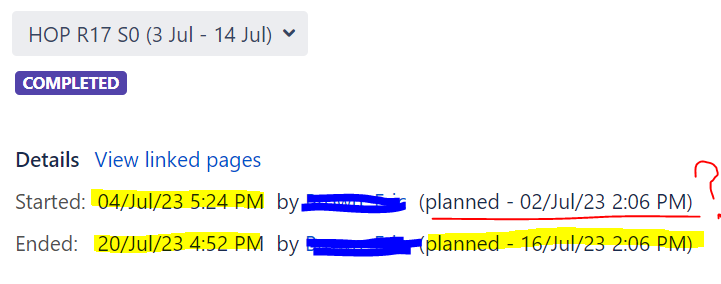
Jira Version:
Jira Data Center On-Premise
-
Related request:
It doesn't make sense to me that we are deleting data (overwriting `start_date` with `activated_date`) from the Jira on-premise edition just to stay "consistent" with the lack of such data on the Jira cloud edition. Could you separate these two fields for both editions and just leave `activated_date` NULL if there's no data?
Please sign in to leave a comment.
Comments
1 comment